
基于JAVA技术爬虫爬网站图片设计与实现(JSP,MySQL)(含录像)

1.无需注册登录,支付后按照提示操作即可获取该资料.
2.资料以网页介绍的为准,下载后不会有水印.资料仅供学习参考之用.
密 惠 保
基于JAVA技术爬虫爬网站图片设计与实现(JSP,MySQL)(含录像)(开题报告,毕业论文12000字,程序代码,MySQL数据库,答辩PPT)
本文通过主题爬虫实现对与图片相关信息的搜集,存储在数据库中,并将这些信息在web端分类显示,同时在web端提供信息检索功能,登录注册功能,信息评论功能。主题爬虫的实现采用向量空间模型进行主题判别,增强型PangRank算法(EPR算法)进行URL筛选。
系统概述
传统的网络爬虫技术主要应刷于抓取静态Web网页l 31.随着AJAX/Web2.0的流行,如何抓取AJAX等动态页面成了搜索引擎急需解决的问题,因为AJAX
颠覆了传统的纯HTTP请求/响应协议机制,如果搜索引擎依旧采用“爬”的机制,是无法抓取到AJAX页面的有效数据的。AJAX采用了JavaScript驱动的异步请求/响应机制.以往的爬虫们缺乏JavaScript语义上的理解.基本上无法模拟触发JavaScript的异步调用并解析返回的异步回渊逻辑和内容另外.在AJAX的应用中,JavaScript会对D0M结构进行大量变动,甚至页面所有内容都通过JavaScript直接从服务器端读取并动态绘制出来。这对习惯了D0M结构相对不变的静态页面简直是无法理解的由此可以看出.以往的爬虫是基于协议驱动的,而对于AJAX这样的技术,所需要的爬虫引擎必须是基于事件驱动的。要实现事件驱动,首先需要解决JavaScript的交互分析和解释的问题。
[来源:http://think58.com]
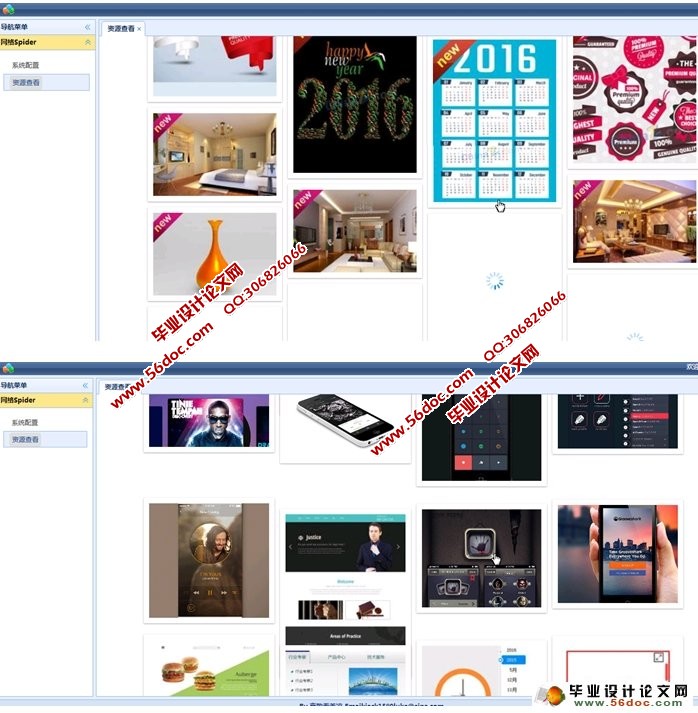
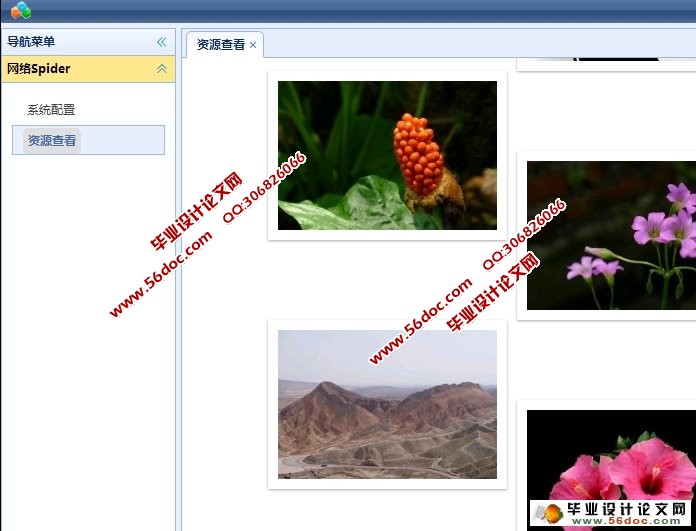
本设计主要研究网络爬虫程序的设计与实现,实现简单的可在后台自动运行的爬虫程序。爬取各个网站并下载图片到服务器,展示图片,图片展示应用瀑布流,响应用户请求。
开发环境:Myeclipse
Web服务器:Tomcat
数据库:Mysql
[资料来源:http://think58.com]
目 录 [资料来源:www.THINK58.com]
1 前 言 1
2 系统概述 2
2.1 课题背景与意义 2
2.1.1 课题开发背景 2
2.1.2 课题开发意义 2
2.2 课题开发工具 3
2.2.1 JAVA和JSP技术简介 3
2.2.2 Tomcat 6.0服务器架构 4
2.2.3 MyEclipse介绍 5
2.2.4总体开发 6
2.3 开发及运行环境 6
3 系统分析 8
3.1 系统概述 8
3.2 系统功能分析 8
3.2.1 可行性分析 8
3.2.2 具体功能分析 8
3.3搜索引擎的分类 9
l、全文索引式搜索引擎 9
2、垂直搜索引擎 9
3、元搜索引擎 9
4、目录索引式搜索引擎 9
5、其他非主流搜索引擎形式: 10
4 系统设计 10
[资料来源:http://www.THINK58.com]
4.1 数据库设计 10
4.1.1 数据库总体设计 10
4.1.2 数据库逻辑设计 11
4.2 系统总体设计 14
4.2.1 总体设计 14
4.2.2 系统逻辑处理 14
4.3 功能设计 15
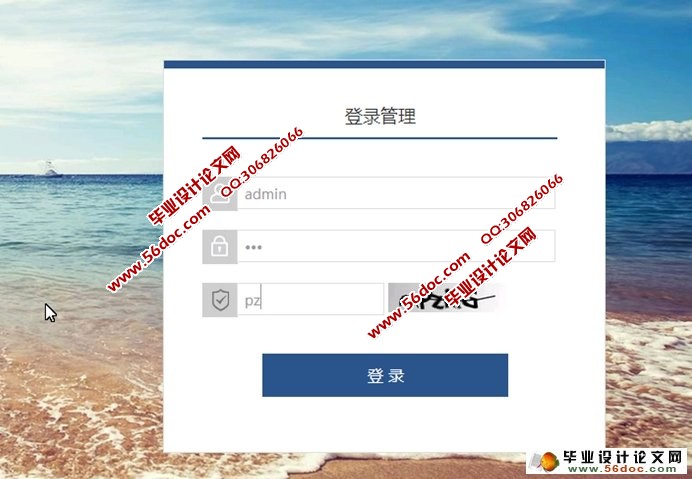
4.3.1 网站登录页 15
4.3.2 系统界面 16
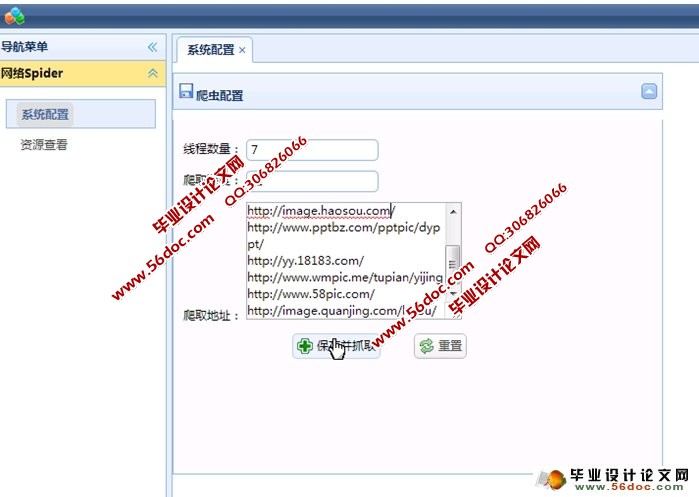
4.3.3 系统配置 17
5 系统实现与调试 18
5.1 系统实现概论 18
5.2 系统功能实现 18
5.2.1 文件结构图 18
5.2.2 文件详细结构图 20
5.3 关键技术实现 20
5.3.1 web.xml 20
5.3.2 数据库db_shopSystem连接部分 22
5.3.3 定时任务扫秒xml文件获取爬虫接口数据 23
5.4 调试过程中的常见错误 24
5.4.1 JDK配置错误 24
5.4.2 SQL空指针异常 25 [来源:http://think58.com]
5.4.3 数据库连接错误 25
6 结 论 26
致 谢 27
参 考 文 献 28 [资料来源:http://think58.com]
上一篇:多媒体素材管理系统的设计与实现(JSP,MySQL)(含录像)
下一篇:二手汽车交易网站的设计与实现(SSH,MySQL)(含录像)