
图像的检索技术的设计与实现

1.无需注册登录,支付后按照提示操作即可获取该资料.
2.资料以网页介绍的为准,下载后不会有水印.资料仅供学习参考之用.
密 惠 保
摘 要
在网络和多媒体技术越来越发达的今天,信息检索技术成了现在计算机领域的重要内容,而图像检索技术又正是这其中的重要内容之一。而网络资源的极大丰富以及图像检索技术不断发展成熟,使得图像检索技术的应用领域不断扩大,这为图像检索技术的继续研究提供条件。
人们为了对图像进行更好的使用和组织管理,便开发出了多种多样图像检索技术,本文首先要将各种图像检索技术的工作原理、研究现状、相关图像搜索引擎与发展趋势作一个介绍。
随着网络传送速度与计算机信息处理速度的提高,网页中对多媒体信息的使用变得十分普及,特别是图像信息,己经成为表示网页内容不可缺少的组成部分。在实现对网页中文本信息提取的同时,如何再为用户抽取所需的图片资料,是信息检索中一个重要的方面。于是各种基于Web的图像检索系统应运而生。它们采用不同的工作方式,极大地方便了用户对网上图像进行检索。
目前图像检索技术的发展正走向更加成熟和完善,其中Web图像搜索技术也更加完善,本文将介绍这种图像检索技术并阐述Web页中的图像与文本之间的关系,对相似度作出了详细的论述。
[资料来源:http://www.THINK58.com]
关键字: 搜索引擎 图象检索 文本处理 信息检索 相似度 相关性反馈
[资料来源:http://www.THINK58.com]
Study of Web Images Retrieval Technique
Abstract
Today, the network and multimedia technology are more and more developed, retrieval technique of information has become the important content of the computer field now, and picture retrieval technique is exactly one of the important contents among them. And network resources are enriched greatly and picture retrieval technique is developing ripe constantly, make picture application of retrieval technique expand constantly, this offer terms for picture continuation research of retrieval technique.
[资料来源:www.THINK58.com]
People develop varied picture retrieval technique in order to carry on better use and organizational management to the picture , this text should first act as an introduction various kinds of picture operation principle , research current situation , relevant picture search engine and development trend of retrieval technique.
With the improvement of the transfer rate of the network and information processing speeds of the computer, it is popularized very much that the webpage hits the use for information of the multimedia, especially the information of the picture , it shows the component with indispensable content of the webpage that own but become. While realizing drawing the Chinese version information of the webpage, how to collect the necessary picture materials for users again, it is an important respect in information retrieval. Then various kinds of picture retrieval systems based on Web arise at the historic moment. They adopt different working way, help user search to the picture online greatly.
The development of retrieval technique of the picture is moving towards riper and more perfect at present, Web picture too perfect to search for technology among them, this text recommend the picture retrieval technique and explain Web picture and relation of text of page, make detailed argumentation to similar degree ,etc. , search for through experiment model conclusion indicate the high efficiency that the picture searches for. [资料来源:www.THINK58.com]
Keywords: Search engine Image Retrieval Text-processing Information retrieval Similar degree Dependence feedback
近年来随着用户对网上图像搜索要求的不断增长,各种图像搜索引擎应运而生,它们各自以不同的工作方式为用户提供各种检索途径,使网上图像信息的搜索变得非常简单,尽管还不很完善,却已经可以满足用户的大多数要求。 [来源:http://www.think58.com]
1.2.1搜索引擎的工作原理
最基本的搜索引擎的结构,是由Spider不停地从Web网上收集数据,存放在搜索引擎的数据库中。用户通过搜索引擎服务器上的Web接口,提出搜索请求,Web Server通过CGI或其它技术访问数据库,并将用户的搜索请求转换成相应的数据存取语句,送给数据库引擎处理,并把查询结果通过网页显示给用户。
网络搜索的基本原理是通过网络机器人定期在web网页上爬行,然后发现新的网页,把它们取回来放到本地的数据库中,用户的查询请求可以通过查询本地的数据库来得到。
一般来说网络信息检索的实现机制一般有两种,一种是通过手工方式对网页进行索引,它的缺点是Web的覆盖率比较低,同时不能保证最新的信息。查询匹配是通过用户写入的关键字和网页的描述和标题来进行匹配,而不是通过全文的匹配进行的。第二种是对网页进行自动的索引,这种能实现自动的文档分类,实际上采用了信息提取的技术。但是在分类准确性上可能不如手工分类。
在现在所有运行的搜索工具来说,一般都有一个Robot定期的访问一些站点,来检查这些站点的变化,同时查找新的站点。一般站点有一个robot.txt文件用来说明服务器不希望Robot访问的区域,Robot 都必须遵守这个规定。如果是自动索引的话,Robot在得到页面以后,需要对该页面根据其内容进行索引,根据它的关键字的情况把它归到某一类中。页面的信息是通过元数据的形式保存的,典型的元数据包括标题、IP地址、一个该页面的简要的介绍,关键字或者是索引短语、文件的大小和最后的更新的日期。尽管元数据有一定的标准,但是很多站点都采用自己的模板。文档提取机制和索引策略对Web搜索引擎的有效性有很大的关系。高级的搜索选项一般包括:布尔方法或者是短语匹配和自然语言处理。一个查询所产生的结果按照提取机制被分成不同的等级提交给用户。最相关的放在最前面。每一个提取出来的文档的元数据被显示给用户。同时包括该文档所在的URL地址。
[资料来源:THINK58.com]
另外有一些关于某一个主题的专门的引擎,它们只对某一个主题的内容进行搜索和处理,这样信息的取全率和精度相对就比较高。
目前,图像搜索引擎主要通过以下两种方法识别图像:
(1)自动查找图像文件。通过两个HTML标签,即IMGSRC和HREF来检测是否存在可显示的图像文件,IMGSRC表示“显示下面的图像文件”,导向的是嵌入式图像;而HREF则表示“下面是一个链接”,导向的是被链接的图像。搜索引擎通过检查文件扩展名来判断其导向的是否为图像文件,如果文件扩展名是.gif或.jpg,即是一个可显示的图像。
(2)人工干预找出图像。进行分类,由人工对网上的图像及站点进行选择。这种方法可以产生准确的查询体系,但劳动强度太大,因此要限制处理图像的数量。
由于图像不同于文本,需要人们按照各自的理解来说明其蕴含的意义,因此图像检索比文本的查询和匹配要困难得多。
[来源:http://think58.com]
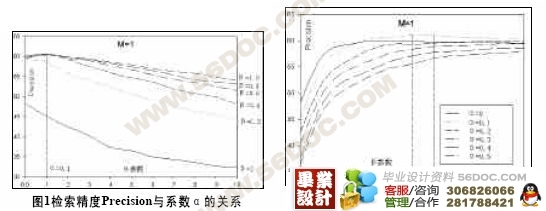

[版权所有:http://think58.com]
[资料来源:THINK58.com]
[来源:http://think58.com]